


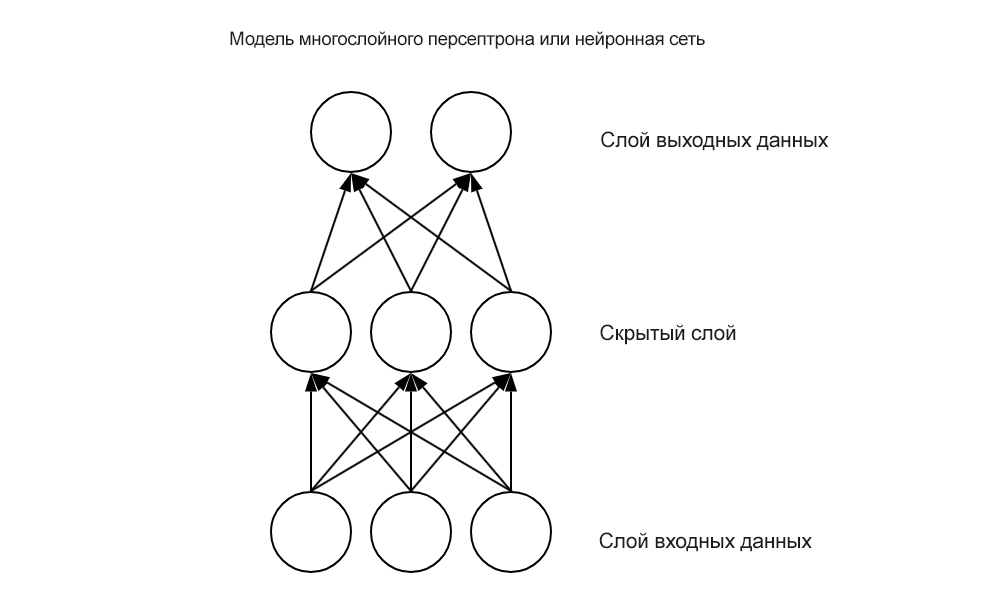
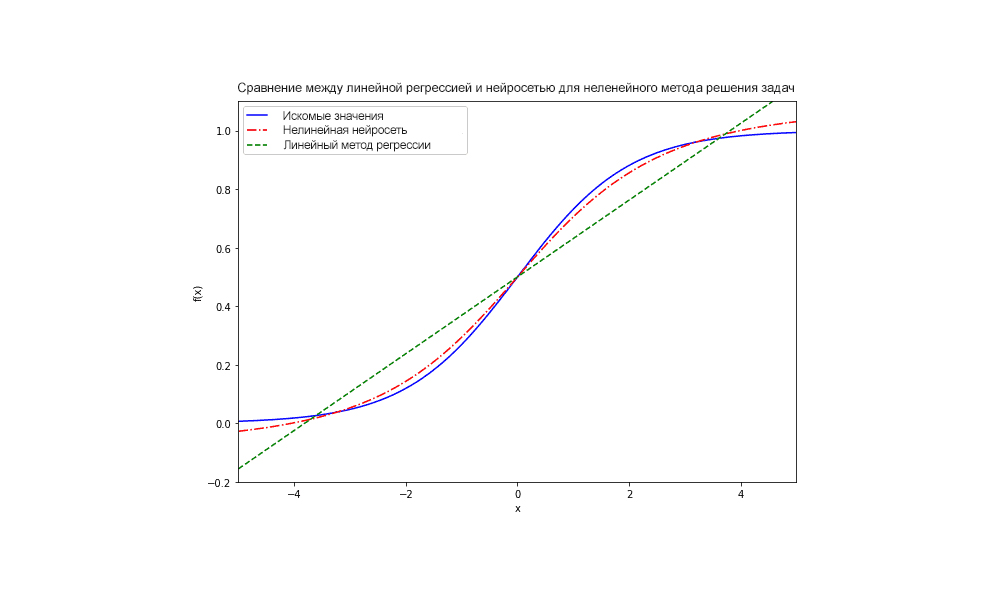
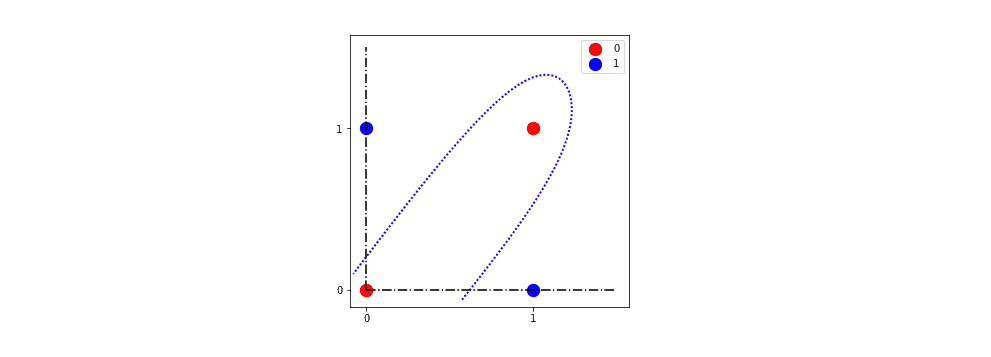
Нейронные сети с прямой связью – это сети узлов, которые передают линейную комбинацию своих входных данных с одного уровня на другой. При этом узлы решают, как модифицировать свои входные данные, используя заданную функцию активации. Функция активации нейрона здесь является ключевой. Выбирая нелинейные функции активации, такие как логистическая функция,  показанная ниже, нейронная сеть может внедрять нелинейность в свою работу:
показанная ниже, нейронная сеть может внедрять нелинейность в свою работу:

В этой задаче автомобиль движется по улице с постоянной скоростью.
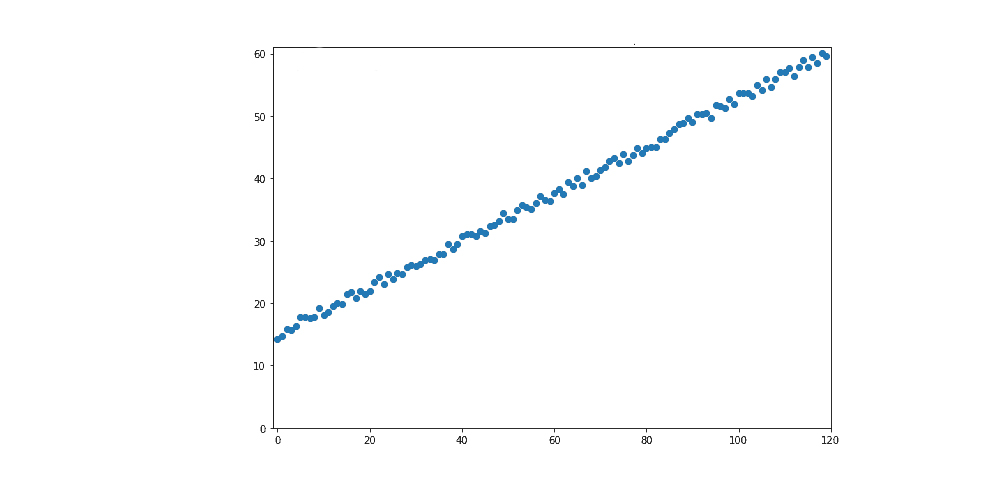
Наша цель – предсказать его местоположение на более позднее время,  . Для этого мы сначала измеряем его положение через несколько интервалов и получаем измерения, показанные на изображении выше.
. Для этого мы сначала измеряем его положение через несколько интервалов и получаем измерения, показанные на изображении выше.
Результатом является достаточно большой набор данных, к которому мы затем применяем нейронную сеть для линейной регрессии. Набор данных на изображении выше включает ошибки в измерениях, как и в любых реальных наборах данных.
Затем мы разделяем набор данных на обучающий и тестовый наборы данных. На обучающем наборе данных мы обучаем глубокую нейронную сеть и измеряем ее точность по сравнению с тестовым набором данных. После нескольких тысяч эпох обучения сеть узнает, что существует следующая взаимосвязь между временем ввода  и положением вывода
и положением вывода  :
:
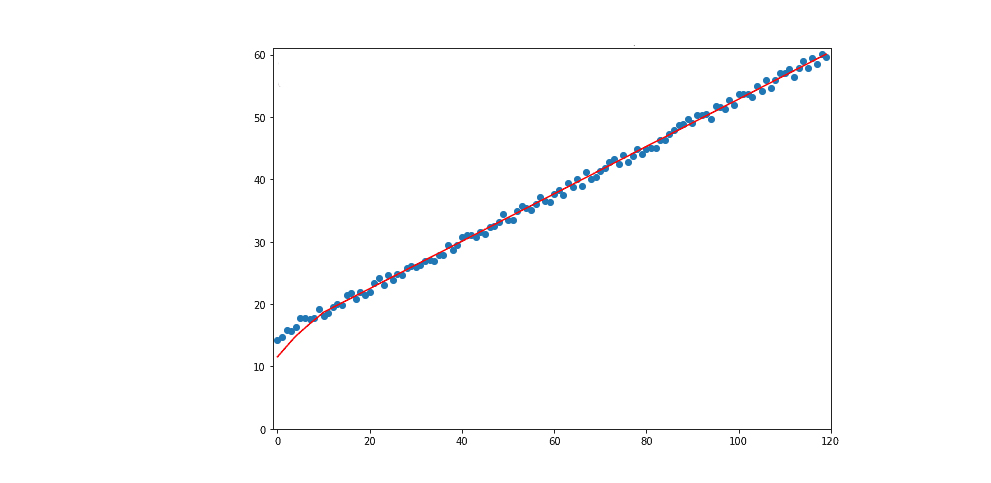
Как это обычно бывает в задачах машинного обучения, мы могли бы измерить точность нашей системы.
Если бы мы сейчас измерили бы точность, то получили бы очень хороший результат на котором можно было бы и остановиться. НО!
Базовые знания в области физики дадут возможность решить эту задачу гораздо проще. Поскольку скорость постоянна, то  и
и  , которые мы можем вычислить вручную.
, которые мы можем вычислить вручную.
Случаи, подобные этому, совсем не редкость на практике, и мы должны иметь их в виду.
Решая новую проблему, мы не должны сразу пытаться использовать машинное обучение.
Если алгоритмические решения неизвестны, только тогда мы должны рассмотреть возможность применения в первую очередь более простых алгоритмов машинного обучения, а во вторую очередь нейронных сетей.