

С начала 90-х годов оптическое распознавание символов (OCR) стало базовой необходимостью для любой организации, работающей с большим объемом документов. Но с постоянно растущей потребностью в бизнес-аналитике и постоянным усовершенствованием искусственного интеллекта OCR приняло новый поворот.
OCR больше не используется только для сканирования документов. При правильном использовании OCR на базе искусственного интеллекта может произвести и, конечно, производит революцию в аналитическом процессе, позволяя предприятиям и бизнесу извлекать неструктурированные данные из документов для более упорядоченной и эффективной аналитики.
В этой статье будет рассмотрено, как внедрение искусственного интеллекта может улучшить технологии оптического распознавания символов, и представлена более полезная информация, в том числе о том, как он работает, какие преимущества он дает, а также текущие ограничения программного обеспечения оптического распознавания символов с помощью искусственного интеллекта.

Что такое распознавание текста на базе искусственного интеллекта?
OCR на базе искусственного интеллекта — это программное решение, которое позволяет предприятиям автоматически извлекать и обрабатывать информацию из различных типов документов, включая счета-фактуры, квитанции, отчеты и многое другое. Программное обеспечение обрабатывает изображения текста и преобразует их в машиночитаемые формы, которые можно анализировать с помощью технологий машинного обучения и глубокого обучения.
При правильном использовании оптическое распознавание текста может обеспечить огромную экономию времени, снижение затрат и количество ошибок, обычно возникающих из-за человеческой ошибки при вводе данных вручную.
Как работает программное решение OCR на базе Ai?
Программное обеспечение OCR на базе искусственного интеллекта работает так же, как обычные машины OCR, но с несколькими ключевыми отличиями. В отличие от традиционных решений OCR, которые используют алгоритмы на основе правил для распознавания символов на изображениях и документах, решение OCR на базе искусственного интеллекта использует технологии компьютерного зрения и машинного обучения для идентификации символов на изображениях и документах, что делает его более точным, чем традиционное OCR.
Некоторое программное обеспечение также поставляется со встроенным программным обеспечением NLP, облегчающим анализ документов. Обычно этот процесс состоит из следующих основных этапов:
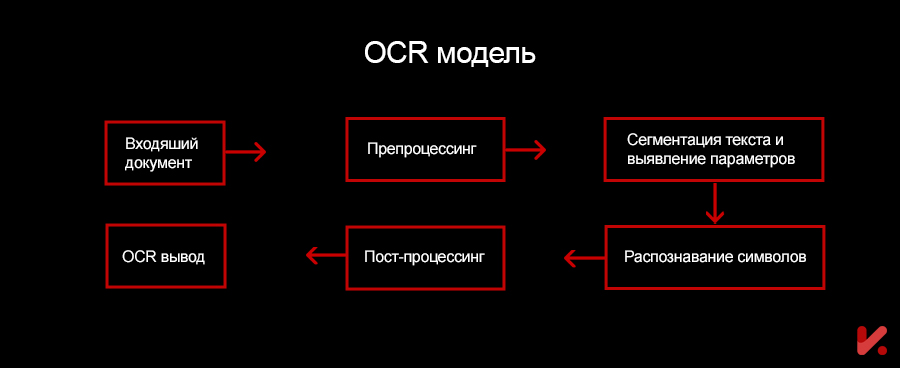
Получение изображения
Через сканер программа оптического распознавания символов считывает документ и преобразует текст в двоичные данные. Это достигается за счет использования технологии компьютерного зрения для определения областей документа, которые могут содержать текст. Это может включать анализ различных визуальных элементов документов, таких как цвет, форма и текстура.
Предварительная обработка
На этом этапе программное обеспечение обрабатывает изображение или документ, чтобы оптимизировать его качество и читаемость. Обычно это включает в себя различные задачи, такие как шумоподавление, поворот изображения, устранение перекоса и настройка контрастности. Используя эти процессы, программное обеспечение гарантирует четкость и четкость изображения, что упрощает последующие шаги.
Сегментация текста
Сегментация текста обычно включает в себя разделение отдельных символов или слов для облегчения дальнейшего распознавания.
Извлечение параметров
Затем программное обеспечение извлекает соответствующие функции из сегментированного текста. Эти функции обычно включают в себя различные характеристики текста, включая форму, статистические свойства и текстуру.
Распознавание символов
Извлеченные функции анализируются с использованием алгоритмов машинного обучения, обученных на больших наборах данных с пометками, что позволяет им изучать закономерности и взаимосвязи между функциями документа и соответствующими словами или символами. Это позволяет программному обеспечению назначать метки сегментированным текстовым областям и распознавать текстовое содержимое внутри изображений.
Постобработка
Основная цель постобработки — обеспечить более высокую точность и улучшить общее качество распознанного текста. Сюда входят различные задачи, такие как проверка на основе контекста, проверка орфографии и исправление ошибок.
После предварительной обработки программное обеспечение OCR преобразует распознанный текст в цифровой формат, который можно далее обрабатывать и анализировать.
Как OCR на базе ИИ меняет обработку и анализ документов
OCR на базе искусственного интеллекта может произвести революцию в анализе документов . Вот некоторые способы повышения точности и эффективности этого процесса:
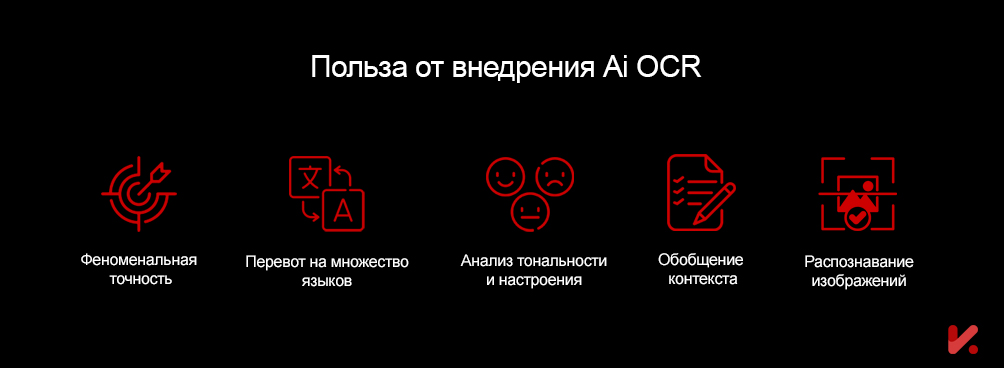
Повышенная точность и эффективность
В отличие от традиционных OCR, которые для распознавания текста полагаются на алгоритмы, основанные на правилах, OCR на базе искусственного интеллекта используют усовершенствованные алгоритмы распознавания. Эти алгоритмы включают в себя алгоритмы глубокого и машинного обучения, которые лучше приспособлены для расширенного распознавания символов. Они достигают этого, обучаясь на основе массива данных в своих наборах обучающих данных, что позволяет им адаптироваться к различным шрифтам, языкам и стилям, что приводит к более точному и надежному извлечению данных.
Программное обеспечение OCR на базе искусственного интеллекта также может автоматически обнаруживать ошибки и несоответствия, такие как орфографические ошибки и недостающие данные в документах. Это устраняет необходимость ручной корректуры и одновременно повышает общее качество данных.
Языковой перевод
Транснациональные организации, работающие в разных регионах, часто испытывают трудности с анализом документов из разных отраслей из-за языкового барьера. Традиционно эти организации полагались на переводчиков-людей, но появление цифровых систем перевода изменило ситуацию. При этом необходимость обработки документов с использованием нескольких систем в разных штатах может быть довольно трудоемкой и трудоемкой.
К счастью, некоторые программы оптического распознавания символов имеют возможности языкового перевода, которые позволяют автоматически переводить текст в отсканированных документах на предпочитаемый язык. И, в отличие от традиционных систем перевода, программное обеспечение OCR на базе искусственного интеллекта также может переводить другие тонкости речи, включая культурные нюансы и идиоматические выражения, которые часто теряются в традиционных методах. Это обеспечивает полноценный перевод, который позволяет проводить более эффективный анализ.
Анализ настроений
Обратная связь с клиентами является неотъемлемой частью понимания настроений клиентов по отношению к конкретным продуктам и услугам. Это то, что позволяет организациям оценивать успех различных проектов. К сожалению, большая часть отзывов клиентов в виде физических документов анализируется в основном сотрудниками-людьми, которые могут не получить полной картины.
Предприятия могут извлечь выгоду из программного обеспечения OCR, объединенного с технологиями глубокого обучения, которые позволяют им анализировать текстовые данные, извлекать важную информацию и классифицировать ее на положительные, отрицательные или нейтральные настроения.
Благодаря этой информации предприятия смогут лучше принимать решения на основе данных и определять области для улучшений. Это также помогает определить потребности, интересы и модели поведения клиентов.
Обобщение документов
Резюмирование является неотъемлемой частью анализа документа. Обобщая ключевые моменты, сотрудникам легче просматривать большие объемы данных и принимать обоснованные решения. Этот процесс можно сделать еще более простым с помощью оптического распознавания символов на базе искусственного интеллекта.
Системы оптического распознавания символов на базе искусственного интеллекта используют обработку естественного языка, машинное обучение и технологии глубокого обучения для предоставления текстовых сводок во время постобработки. Эти инструменты могут выявлять и удалять избыточность в текстовых данных и предлагать персонализированные сводки.
Распознавание изображений
В отличие от традиционных систем оптического распознавания символов, оптическое распознавание текста на основе искусственного интеллекта может распознавать не только текст, но также людей и объекты для упрощения визуальной обработки. Он может обнаруживать и идентифицировать объекты и текст на изображениях, распознавать лица и классифицировать захваченные данные по различным категориям для облегчения анализа.
Узнайте больше о проблемах конфиденциальности при анализе документов на основе искусственного интеллекта
Другие преимущества программного обеспечения OCR на базе искусственного интеллекта для бизнеса
Интеллектуальная автоматизация
Интеллектуальная автоматизация имеет решающее значение для любого бизнеса, стремящегося получить конкурентное преимущество в цифровой экономике. Однако многие компании не могут осознать преимущества бизнес-аналитики, поскольку большая часть их данных находится в форме физических документов, для анализа которых требуется много времени и энергии.
К счастью, с помощью OCR компании могут избавиться от долгих, утомительных и полных ошибок задач по вводу данных, связанных с анализом документов вручную. OCR на базе искусственного интеллекта делает еще один шаг вперед, оптимизируя процессы, делая их более масштабируемыми и эффективными. Таким образом, предприятия могут автоматически извлекать и анализировать текстовые данные из документов, используя единую систему.
Улучшенная безопасность данных
Одним из самых больших рисков при обращении с физическими документами является риск их потери по халатности или в результате несчастного случая. И как только они уйдут, вернуть их уже невозможно. Бумажные документы также имеют очень короткий срок службы и занимают много места для хранения.
Благодаря технологии OCR компании могут легко преобразовывать свои бумажные документы в цифровые форматы, которые гораздо безопаснее хранить и обрабатывать. Программное обеспечение на базе искусственного интеллекта также предлагает варианты облачного хранения, которые предлагают больше гарантий безопасности для конфиденциальных документов.
Снижение затрат
Помимо упрощения и ускорения процесса извлечения информации из физических документов, технология оптического распознавания символов на основе искусственного интеллекта может обеспечить значительную экономию средств при анализе документов. Очень часто единовременная или даже подписная стоимость приобретения оборудования и программного обеспечения для оптического распознавания символов намного дешевле, чем наем сотрудников для обработки и анализа документов вручную.
Повышенная эффективность
Одним из наиболее заметных преимуществ технологии искусственного интеллекта во всех аспектах бизнеса является повышение эффективности. Что касается обработки и анализа документов, технология оптического распознавания символов на основе искусственного интеллекта может помочь анализировать, организовывать и обрабатывать документы быстрее, чем это мог бы сделать любой человек. В конечном итоге это приводит к тому, что больший объем работы выполняется за более короткий промежуток времени, тем самым высвобождая время сотрудников, чтобы они могли сосредоточиться на других обязанностях.
Текущие прорывные достижения OCR
Помимо описанных преимуществ есть те, которые стали доступны сравнительно недавно. На момент написания статьи (февраль 2024 г.) эти прорывные технологии уже внедрены в многие модели нейронных сетей.
Некоторые из наиболее заметных достижений включают в себя:
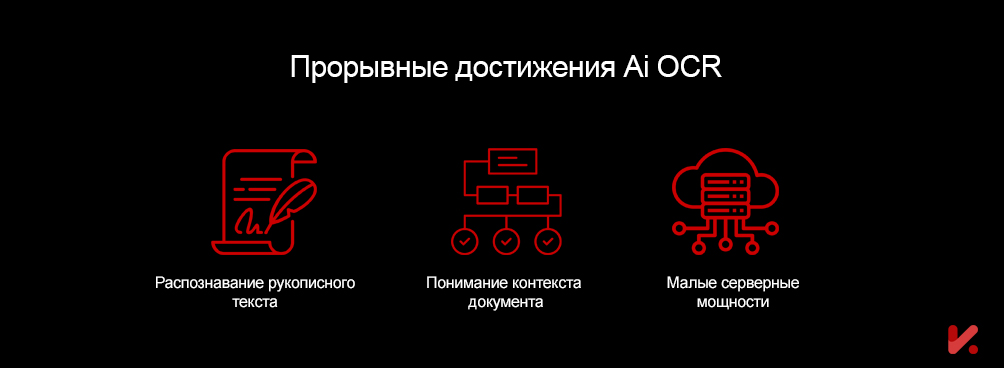
Распознавание рукописного текста
Распознавание рукописного текста, которое раньше казалось непосильной задачей, теперь стало доступным и легким для почти любого почерка. Современные системы OCR (Optical Character Recognition) обладают высокой точностью и способны распознавать даже самые запутанные почерки. Благодаря использованию нейронных сетей и машинному обучению, эти системы обучаются на большом количестве образцов рукописного текста, что позволяет им адаптироваться к различным стилям и особенностям письма. Теперь любой бизнес сможет преобразовать свои рукописные заметки или документы в электронный вид, сэкономив время и упростив процесс работы с текстом.
Понимание контекста документа
Понимание контекста документа является важной задачей для многих приложений обработки текста. Это позволяет системам более точно интерпретировать и анализировать содержимое документа, учитывая его смысл и целевую аудиторию.
Одним из примеров использования понимания контекста является автоматическое извлечение информации из текстовых документов. Системы могут распознавать ключевые слова, фразы или концепции, связанные с определенным контекстом, такими как юридические документы, медицинские записи или финансовые отчеты. Это позволяет системам эффективно обрабатывать большие объемы текста и извлекать нужную информацию для дальнейшего анализа или принятия решений.
Кроме того, понимание контекста помогает системам лучше интерпретировать значение слов и фраз в зависимости от контекста, в котором они используются. Например, слово “банк” может иметь разные значения в контексте финансовой индустрии и в контексте географии. Системы, способные понимать контекст, могут более точно определить значение слова, исходя из окружающего текста.
Понимание контекста также может быть полезным при автоматическом переводе текста. Системы могут учитывать контекст предложения или абзаца, чтобы более точно перевести фразы и сохранить смысл оригинального текста.
Требования к вычислительной мощности
Современные OCR-системы стали доступными и легкими в использовании для почти любого проекта. Теперь нет необходимости в мощных локальных вычислительных ресурсах или специализированном оборудовании.
Благодаря серверным требованиям, OCR может быть реализован на удаленных серверах, что позволяет снизить нагрузку на клиентскую инфраструктуру.
Это особенно полезно для проектов с ограниченными ресурсами или сетевыми ограничениями. Сегодня разработчики могут использовать готовые OCR-сервисы API, которые предоставляют широкий спектр функций и возможностей. Это упрощает интеграцию OCR в приложения и позволяет быстро и эффективно обрабатывать текст из различных источников, таких как изображения или сканы документов. В результате, использование OCR стало доступным практически для любого проекта, независимо от его масштаба или сложности.
Заключение:
OCR прошел долгий путь: от традиционных систем, основанных на правилах, которые могли распознавать только печатный текст, до программного обеспечения на базе искусственного интеллекта, которое может распознавать текст на изображениях и даже рукописный текст.
При правильном использовании технология оптического распознавания символов на основе искусственного интеллекта может изменить правила игры для предприятий во многих секторах, позволяя им беспрепятственно обрабатывать, анализировать и хранить документы.